Getting Started
A key limitation of XGBoost and other tree-based algorithms.

If you’ve ever competed in machine learning competitions on Kaggle or browsed articles or forums written by the data science community, you’ve probably heard of XGBoost. It’s the algorithm that has won many Kaggle competitions and there are more than a few benchmark studies that show instances in which XGBoost consistently outperforms other algorithms. The fact that XGBoost is parallelized and runs faster than other implementations of gradient boosting only adds to its mass appeal.
For those who are unfamiliar with this tool, XGBoost (which stands for “Extreme Gradient Boosting”) is a highly optimized framework for gradient boosting, an algorithm that iteratively combines the predictions of several weak learners such as decision trees to produce a much stronger and more robust model. Since its inception in 2014, XGBoost has become the go-to algorithm for many data scientists and machine learning practitioners.
“When in doubt, use XGBoost” — Owen Zhang, Winner of Avito Context Ad Click Prediction competition on Kaggle
This probably sounds too good to be true, right? XGBoost is definitely powerful and useful for many tasks, but there is one problem… In fact, this is a problem that affects not only XGBoost but all tree-based algorithms in general.
Tree-Based Models Are Bad at Extrapolation
This is perhaps the fundamental flaw inherent in all tree-based models. It doesn’t matter if you have a single decision tree, a random forest with 100 trees, or an XGBoost model with 1000 trees. Due to the method with which tree-based models partition the input space of any given problem, these algorithms are largely unable to extrapolate target values beyond the limits of the training data when making predictions. This is usually not a huge problem in classification tasks, but it is definitely a limitation when it comes to regression tasks that involve predicting a continuous output.
If the training dataset only contains target values between 0 and 100, a tree-based regression model will have a hard time predicting a value outside of this range. Here are some examples of predictive tasks in which extrapolation is important and XGBoost might not do the trick…
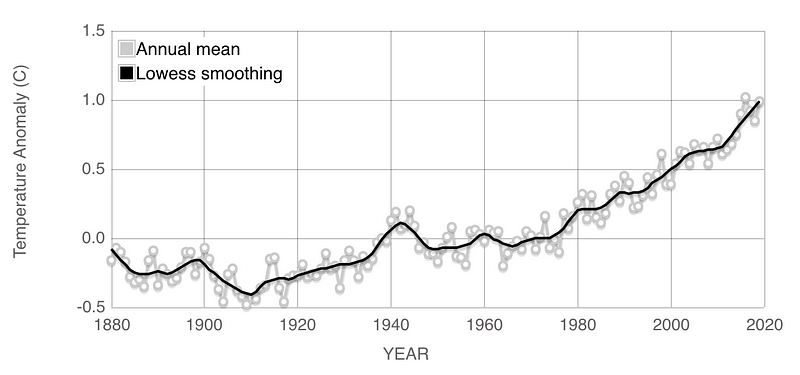
Predicting the Impact of Climate Change on Global Temperatures
Over the last 100 years, global temperatures have risen at an increasing rate. Imagine trying to predict the global temperatures for the next 20 years using data from 1900 to 2020. A tree-based algorithm like XGBoost will be bounded by the highest global temperatures as of today. If the temperatures continue to rise, the model will surely underestimate the rise in global temperatures over the next 20 years.
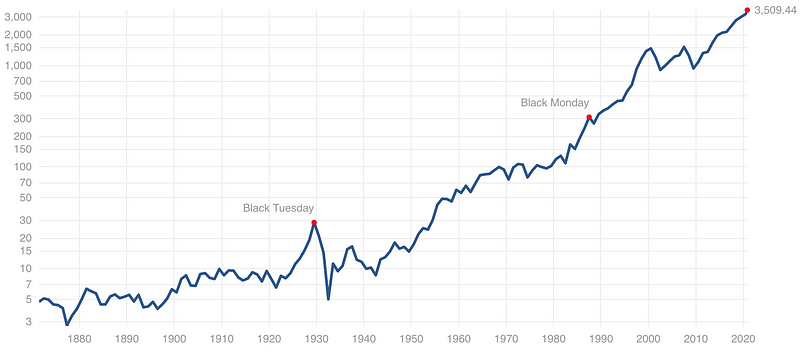
Predicting the Prices of a Stock Market Index Such as the S&P 500
If we look at the trends of a popular stock market index like the S&P 500 over the last 50 years we will find that the price of the index goes through highs and lows but ultimately increases over time. In fact, the S&P 500 has an average annual return of around 10 percent based on historical data, meaning the price goes up by around 10 percent on average each year. Just try to forecast the price of the S&P 500 using XGBoost and you’ll see that it may predict decreases in prices, but fails to capture the overall increasing trend in the data. To be fair, predicting stock market prices is an extremely difficult problem that even machine learning hasn’t solved, but the point is, XGBoost can’t predict increases in prices beyond the range present in the training data.
Forecasting Web Traffic
This task was the goal of the following Kaggle competition that I participated in a few years ago. Just as XGBoost may fail to capture an increasing trend in global temperatures or stock prices, if a webpage is going viral then XGBoost may not be able to predict the increase in traffic to that page even if the increasing trend is obvious.
The Math Behind Why Trees Are Bad at Extrapolation
Decision trees take the input space and partition it into subsections which each correspond to a singular output value. Even in regression problems, a decision tree uses a finite set of rules to output one of a finite set of possible values. For this reason, a decision tree used for regression will always struggle to model a continuous function. Consider the following example where a decision tree can be used to predict the price of a house. Keep in mind the dataset I created below is completely made up and only used for the purpose of proving a point.
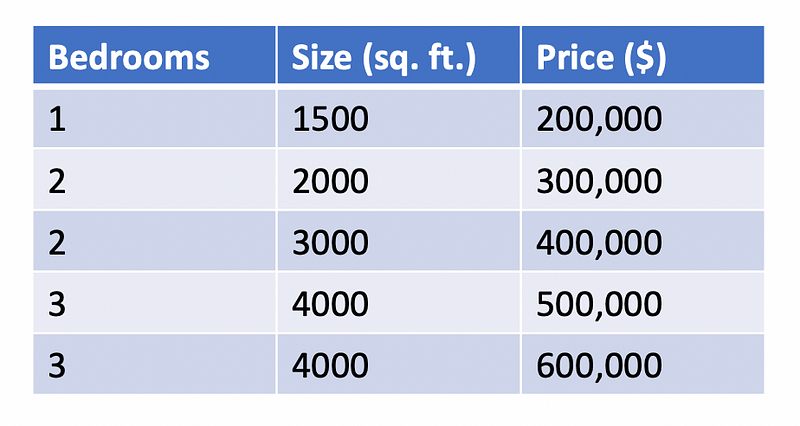
If we used this small dataset to train a decision tree, the following tree might end up being our model for predicting housing prices.
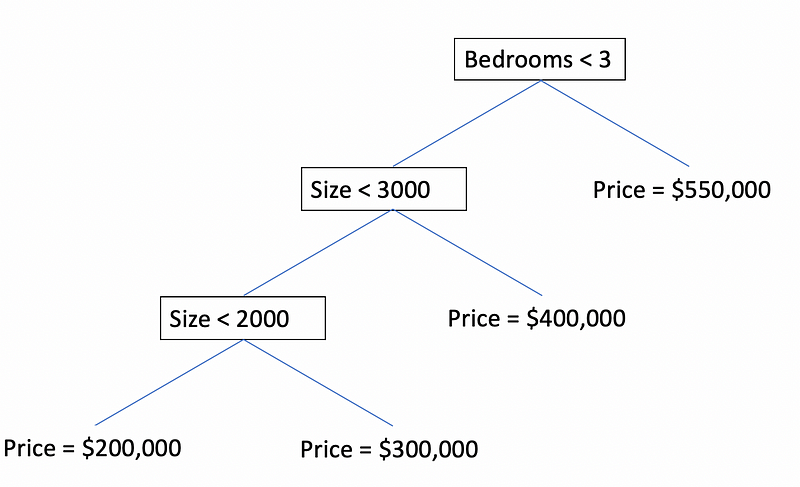
Obviously, this is not a very good model or a good dataset, but it demonstrates one of the fundamental issues with decision tree regression. According to the dataset, it seems that the number of bedrooms and the size of a house is positively correlated with its price. In other words, larger houses with more bedrooms will cost more than smaller houses with fewer bedrooms. This seems logical, but the decision tree will never predict a price below $200,000 or a price above $550,000 because it has partitioned the infinite input space into a finite set of possibilities. Since decision tree regression models assign values to leaves based on averages, note that since there are two 4000 square-foot houses with three bedrooms, the decision tree predicts the average price of the two houses ($550,000) for this condition. Even though a $600,000 house exits in the dataset, the decision tree will never be able to identify a $600,000 house.
Even if a model like XGBoost computed a weighted average of 1000 decision trees, each decision tree would be limited to predicting only a set range of values and as a result, the weighted average is also limited to a predetermined range of values depending on the training data.
What Tree-Based Models Are Good at Doing
While tree-based models are not good at extrapolation, they are still good at solving a wide range of machine learning problems. XGBoost generally can’t predict the future very well, but it is well suited for tasks such as the following:
- Classification problems, especially those related to real-world business problems such as fraud detection or customer churn prediction. The combined rule-based logic of many decision trees can detect reasonable and explainable patterns for approaching these classification problems.
- Situations in which there are many categorical variables. The rule-based logic of decision trees works well with data including features with categories such as Yes/No, True/False, or Small/Medium/Large.
- Problems in which the range or distribution of target values present in the training set can be expected to be similar to that of real-world testing data. This condition can apply to almost every machine learning problem with training data that has been sampled properly. Generally, the quality of a machine learning model is bounded by the quality of the training data. You can’t train XGBoost to effectively predict housing prices if the price range of houses in the dataset is between $300K and $400K. There will obviously be many houses that are less and more expensive than those in the training set. For problems like predicting housing prices, you can fix this issue with better training data, but if you are trying to predict future stock prices, XGBoost simply will not work because we don’t know anything about the range of target values in the future.
What You Should Use Instead for Extrapolation
For forecasting or any machine learning problem involving extrapolation, neural networks will generally outperform tree-based methods. Unlike tree-based algorithms, neural networks are capable of fitting any continuous function, allowing them to capture complex trends in data. In the theory behind neural networks, this statement is known as the universal approximation theorem. This theorem essentially states that a neural network with just one hidden layer of arbitrary size can approximate any continuous function to any desired level of precision. Based on this theorem, a neural network can capture an increasing trend in stock prices or a rise in global temperatures and can predict values outside the range of the training data.
For time-series forecasting problems such as forecasting global temperatures, recurrent neural networks with LSTM (long short-term memory) units can be very effective. In fact, LSTMs work well with sequential data in general and I even used them for text classification in this article.
Does that mean neural networks are better than XGBoost?
No, not necessarily. Neural networks are better than XGBoost for some but definitely not all problems. In machine learning, there is “no free lunch” and there is a price that you pay for the advantages of any algorithm.
In fact, while the generalization power of neural networks is a strength it is also a weakness because a neural network can fit any function and can also easily overfit the training data. Neural networks also tend to require larger amounts of training data to make reasonable predictions. Interestingly, the same complexity that makes neural networks so powerful is the same complexity that makes them much harder to explain and interpret compared to tree-based algorithms.
The moral of the story is that not all algorithms were created equal, but every algorithm has flaws and no algorithm is universally superior across all machine learning problems and business use cases.
Summary
- XGBoost is an incredibly sophisticated algorithm but like other tree-based algorithms, it falls short when it comes to tasks involving extrapolation.
- XGBoost is still a great choice for a wide variety of real-world machine learning problems.
- Neural networks, especially recurrent neural networks with LSTMs are generally better for time-series forecasting tasks.
- There is “no free lunch” in machine learning and every algorithm has its own advantages and disadvantages.
Sources
- T. Chen, C. Guestrin, XGBoost: A Scalable Tree Boosting System, (2016), the 22nd ACM SIGKDD International Conference.
- Kaggle, Avito Context Ad Clicks, (2015), Kaggle Competitions.
- NASA Goddard Institute for Space Studies (GISS), Global Temperature, (2020), Global Climate Change: Vital Signs of the Planet.
- Standard & Poor, S&P 500 Historical Prices, (2020), multpl.com.
- Wikipedia, Universal approximation theorem, (2020), Wikipedia the free encyclopedia.