How you can build more robust models using stacking.

Introduction
In the last two decades, ensemble methods such as random forests and gradient boosting, which combine several instances of the same types of models using voting or weighted averaging to produce strong models, have become extremely popular. However, there is another approach that allows us to reap the benefits of different models by combining their individual predictions using higher-level models.
Stacked generalization, also known as stacking, is a method that trains a meta-model to intelligently combine the predictions of different base-models.
The goal of this article is to not only explain how this competition-winning technique works but to also demonstrate how you can implement it with just a few lines of code in Scikit-learn.
How Stacking Works
Every machine learning model has advantages and disadvantages due to the bias created by the assumptions behind the model. This is a concept that I mentioned in my previous post about the “no free lunch” theorem for supervised machine learning.
https://towardsdatascience.com/what-no-free-lunch-really-means-in-machine-learning-85493215625d
Different machine learning algorithms may be skilled at solving problems in different ways. If we had multiple algorithms working together to solve a problem, one algorithm’s strengths could potentially mask the other algorithm’s weaknesses and vice versa. This is the idea behind stacking.
Stacking involves training multiple base-models to predict the target variable in a machine learning problem while at the same time, a meta-model learns to use the predictions of each base model to predict the value of the target variable. The figure below demonstrates this idea.
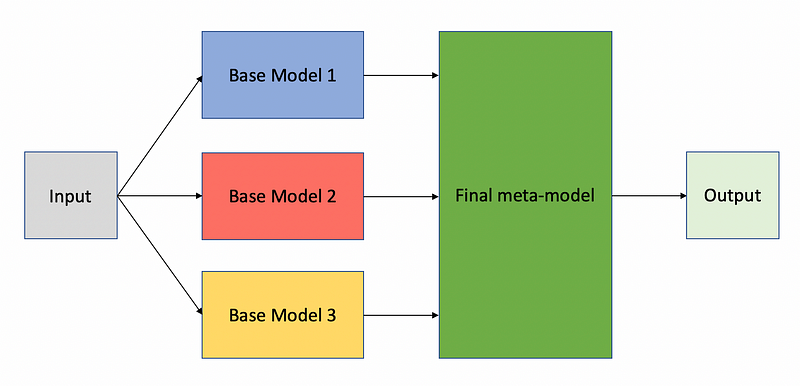
The algorithm for correctly training a stacked model follows these steps:
- Split the data into k-folds just like in k-fold cross-validation.
- Select one fold for validation and the remaining k-1 folds for training.
- Train the base models on the training set and generate predictions on the validation set.
- Repeat steps 2–3 for the remaining k-1 folds and create an augmented dataset with the predictions of each base model included as additional features.
- Train the final meta-model on the augmented dataset.
Note that each part of the model is trained separately, and the meta-model learns to use both the predictions of the base models and the original data to predict the final output.
For those who are unfamiliar with k-fold cross-validation, it is a technique in which the data for a machine learning problem is split into k-folds or distinct subsets and the model is evaluated iteratively across all the k-folds. In each iteration, one fold is used for evaluation, and the remaining k-1 folds are used for training the model.
The use of a k-fold cross-validation split ensures that the base models are generating predictions on unseen data because the base models will be retrained on different training sets in each iteration.
The power of stacking lies in the final step, in which the meta-model can actually learn the strengths and weaknesses of each base model and intelligently combine their predictions to produce the final output.
Practical Example Using Scikit-Learn
The StackingClassifier and StackingRegressor modules were introduced in Scikit-learn 0.22. So make sure you upgrade to the latest version of Scikit-learn to follow along with this example using the following pip command:
pip install --upgrade scikit-learn
Importing Basic Libraries
Most of the basic libraries I imported below are commonly used in data science projects and should come as no surprise. However, I also made use of the make_classification function from Scikit-learn to generate some synthetic data and I also used Plotly to build interactive plots. In order to embed the interactive plots, I also made use of Datapane.
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.datasets import make_classification
import plotly.graph_objects as go
import datapane as dp
%matplotlib inline
Generating the Dataset
Scikit-learn’s make_classification function is useful for generating synthetic datasets that can be used for testing different algorithms. The dataset I am generating in this scenario is designed to represent a binary classification problem with a realistic level of difficulty based on the following parameters:
- n_features — the number of features in the dataset, which I set to 20.
- n_informative and n_redundant — the number of informative and redundant features in the dataset. I included five redundant features to make the problem harder.
- n_clusters_per_class — the number of clusters included in each class. Higher values make the problem more difficult so I set this value to five clusters.
- class_sep — controls the separation between clusters/classes. Larger values make the task easier so I chose a value of 0.7 which is lower than the default of 1.0.
- flip_y — specifies the percent of class labels that will be assigned at random. I set this value to 0.03 to add some noise to the dataset.
X, y = make_classification(n_samples=50000,
n_features=20,
n_informative=15,
n_redundant=5,
n_clusters_per_class=5,
class_sep=0.7,
flip_y=0.03,
n_classes=2)
Training and Evaluating Individual Models
In order to get a baseline level of performance to compare against the stacked model, I trained and evaluated the following base models:
- Random forest with 50 decision trees
- Support vector machine (SVM)
- K-nearest neighbors (KNN) classifier
The models are all stored in a dictionary for code reusability.
from sklearn.ensemble import RandomForestClassifier
from sklearn.svm import SVC
from sklearn.neighbors import KNeighborsClassifierfrom sklearn.model_selection import cross_val_score, RepeatedStratifiedKFold
from collections import defaultdict
models_dict = {'random_forest': RandomForestClassifier(n_estimators=50),
'svm': SVC(),
'knn': KNeighborsClassifier(n_neighbors=11)}
The models were each validated using a repeated five-fold cross-validation strategy where each fold was repeated with a different random set of samples. In each fold, each model was trained on 80 percent of the data and validated on the remaining 20 percent.
This method results in 10 different accuracy scores for each model which are stored in a dictionary as demonstrated below.
def evaluate_model(model, X, y):
cv = RepeatedStratifiedKFold(n_splits=5, n_repeats=2, random_state=1)
scores = cross_val_score(model, X, y, scoring='accuracy', cv=cv, verbose=1, n_jobs=3, error_score='raise')
return scores
model_scores = defaultdict()
for name, model in models_dict.items():
print('Evaluating {}'.format(name))
scores = evaluate_model(model, X, y)
model_scores[name] = scores
Visualizing the Results for Individual Models
The function defined below takes the dictionary of cross-validation scores for all of the evaluated models and creates an interactive boxplot with Plotly to compare the performance of each model. The function also creates a Datapane report for embedding the plots as I have done in this article.
def plot_results(model_scores, name):
model_names = list(model_scores.keys())
results = [model_scores[model] for model in model_names]
fig = go.Figure()
for model, result in zip(model_names, results):
fig.add_trace(go.Box(
y=result,
name=model,
boxpoints='all',
jitter=0.5,
whiskerwidth=0.2,
marker_size=2,
line_width=1)
)
fig.update_layout(
title='Performance of Different Models Using 5-Fold Cross-Validation',
paper_bgcolor='rgb(243, 243, 243)',
plot_bgcolor='rgb(243, 243, 243)',
xaxis_title='Model',
yaxis_title='Accuracy',
showlegend=False)
fig.show()
report = dp.Report(dp.Plot(fig) ) #Create a report
report.publish(name=name, open=True, visibility='PUBLIC')
plot_results(model_scores, name='base_models_cv')
https://datapane.com/u/AmolMavuduru/reports/base-models?version=2
Based on the boxplot above, we can see that all of the base models have average accuracy scores over 87 percent, but the support vector machine performed the best on average. Surprisingly, a simple KNN classifier, which is often described as a “lazy learning algorithm” because it just memorizes the training data, clearly outperformed the random forest with 50 decision trees.
Defining The Stacked Model
Now let’s see what happens if we train a stacked model. Scikit-learn’s StackingClassifier has a constructor that requires a list of base models, along with the final meta-model that produces the final output. Note that in the code below, this list of base models is formatted as a list of tuples with the model names and model instances.
The stacked model uses a random forest, an SVM, and a KNN classifier as the base models and a logistic regression model as the meta-model that predicts the output using the data and the predictions from the base models. The code below demonstrates how to create this model with Scikit-learn.
from sklearn.ensemble import StackingClassifier
from sklearn.neural_network import MLPClassifier
from sklearn.linear_model import LogisticRegressionCV
base_models = [('random_forest', RandomForestClassifier(n_estimators=50)),
('svm', SVC()),
('knn', KNeighborsClassifier(n_neighbors=11))]
meta_model = LogisticRegressionCV()
stacking_model = StackingClassifier(estimators=base_models,
final_estimator=meta_model,
passthrough=True,
cv=5,
verbose=2)
Evaluating the Stacked Model
In the code below, I simply reused the function I defined earlier for obtaining cross-validation scores for models and used it to evaluate the stacked model.
stacking_scores = evaluate_model(stacking_model, X, y)
model_scores['stacking'] = stacking_scores
Visualizing and Comparing the Results
I reused the plotting function defined earlier to compare the performance of the base models to the stacked model using side-by-side boxplots.
plot_results(model_scores, name='stacking_model_cv')
https://datapane.com/u/AmolMavuduru/reports/stacking-model-cv
Based on the plot above, we can clearly see that stacking produced an improvement in performance, with the stacked model outperforming all of the base models and achieving a median accuracy close to 91 percent. This same process can be repeated for regression problems as well, using the StackingRegressor module from Scikit-learn, which behaves in a similar manner.
Advantages and Disadvantages of Stacking
Like all other methods in machine learning, stacking has advantages and disadvantages. Here are some of the advantages of stacking:
- Stacking can yield improvements in model performance.
- Stacking reduces variance and creates a more robust model by combining the predictions of multiple models.
Keep in mind that stacking also has the following disadvantages:
- Stacked models can take significantly longer to train than simpler models and require more memory.
- Generating predictions using stacked models will usually be slower and more computationally expensive. This drawback is important to consider if you are planning to deploy a stacked model into production.
Summary
Stacking is a great way to take advantage of the strengths of different models by combining their predictions. This method has been used to win machine learning competitions and thanks to Scikit-learn, it is very easy to implement. However, the performance improvements that come from stacking do come with a price in the form of longer training and inference times.
You can find the full code used for the practical example on GitHub. If you liked this article, feel free take a look at some of my recent articles on machine learning below.
https://towardsdatascience.com/what-no-free-lunch-really-means-in-machine-learning-85493215625dhttps://towardsdatascience.com/what-no-free-lunch-really-means-in-machine-learning-85493215625dhttps://towardsdatascience.com/what-no-free-lunch-really-means-in-machine-learning-85493215625d
Sources
- D.H. Wolpert, Stacked Generalization, (1992), Neural Networks.
- F. Pedregosa et al, Scikit-learn: Machine Learning in Python, (2011), Journal of Machine Learning Research.