It doesn’t replace your job, it only makes it a little easier.

In the past five years, one trend that has made AI more accessible and acted as the driving force behind several companies is automated machine learning (AutoML). Many companies such as H2O.ai, DataRobot, Google, and SparkCognition have created tools that automate the process of training machine learning models. All the user has to do is upload the data, select a few configuration options, and then the AutoML tool automatically tries and tests different machine learning models and hyperparameter combinations and comes up with the best models.
Does this mean that we no longer need to hire data scientists? No, of course not! In fact, AutoML makes the jobs of data scientists just a little easier by automating a small part of the data science workflow. Even with AutoML, data scientists and machine learning engineers have to do a significant amount of work to solve real-world business problems. The goal of this article is to explain what AutoML can and cannot do for you and how you can use it effectively when applying it to real-world machine learning problems.
The Data Science Process
As demonstrated in the figure below, based on the Team Data Science Process (TDSP) every data science project can be divided into four phases:
- Defining the business problem.
- Data acquisition and understanding.
- Modeling.
- Model deployment and presentation.
This workflow can be cyclical and it is possible to move to previous steps as we receive new information or project requirements. This is basically an agile approach to delivering data science solutions.
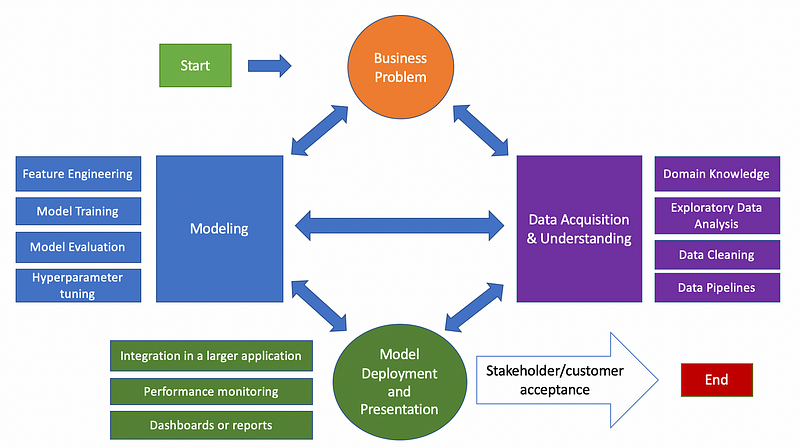
What AutoML Covers in the Data Science Process
What AutoML does for you as a data scientist is it takes care of some of the work in the modeling phase. These are the areas where AutoML can save you time when it comes to the modeling process:
- AutoML can perform automatic feature engineering in the form of selecting features or creating new features from combinations of existing features.
- You no longer have to try and test hundreds or even thousands of hyperparameter combinations to find the best model.
- You no longer have to come up with complex ensemble models using stacking or blending yourself, AutoML solutions may do this for you.
What AutoML Does Not Cover
While AutoML takes care of the complex search process involved in finding the best model and hyperparameter combinations for a given machine learning problem, there are many parts of the data science process that it does not cover such as:
- Understanding the business problem that you are trying to solve.
- Acquiring the domain knowledge necessary to approach the problem.
- Framing the business problem as a machine learning problem.
- Collecting reliable and reasonably accurate data to solve the machine learning problem.
- Cleaning the data and dealing with inconsistencies such as missing or inaccurate values.
- Performing intelligent feature engineering based on your domain knowledge.
- Sanity-checking your models and evaluating your assumptions about the data.
- Integrating your models into existing software applications (some AutoML products may help you with this, but you still have to understand the existing applications).
- Presenting your models to stakeholders and explaining the predictions generated by your model.
- Getting stakeholders and/or customers to trust your models.
This list is clearly much longer than the previous list containing the parts of the data science process covered by AutoML. This is why AutoML can’t replace the jobs of human data scientists, no matter how sophisticated it becomes. It takes human data scientists to understand business problems, use domain knowledge to approach them, and then use this understanding to evaluate the practical effectiveness of the models in a real-world context.
The truth is, in practice, your models are only as good as the data you give them and the assumptions you put into them. You can give an AutoML tool low-quality data and even if it spends hours or days optimizing hyperparameters it will ultimately produce a low-quality model. AutoML makes your life easier as a data scientist, but even with AutoML, you still have a lot of work to do in order to arrive at a business-ready solution.
How You Can Use AutoML Effectively
While AutoML can’t solve all your data science problems for you, it can be valuable if you use it effectively. Here are four principles that you should keep in mind when working with AutoML:
- Understand the requirements of the business problem you are solving.
- Don’t treat the best AutoML model as a black box.
- Always do a sanity check to determine if the model’s predictions make sense.
Understand the requirements of the business problem
In order to evaluate the effectiveness of a machine learning model, you need to understand the business problem that you are trying to solve and the requirements that come with it. AutoML tends to produce complex models when you let it search for the absolute best models for a particular problem. Complex models may be the most accurate, but that doesn’t necessarily mean they are the best for a specific business use case.
Consider the machine learning models behind the speech recognition software that powers virtual assistant technologies such as Siri and Amazon Alexa. These speech recognition models need to produce results in seconds rather than minutes. Imagine saying something to Alexa and waiting five minutes for a response. It would be pretty frustrating and a terrible user experience!
For this reason, one metric that may have been used to evaluate candidate models for this task would be their inference time in a practical situation where a user is talking to a virtual assistant. One model may achieve 99 percent accuracy but take five minutes on average to process the user’s spoken requests while another may achieve 95 percent accuracy and return results in seconds. The faster model is better for this business use case despite its lower testing accuracy.
In the context of AutoML, you may need to ask the following types of questions when evaluating the results of the model search performed by the AutoML tool:
- How fast does the model need to produce results?
- What kind of application are you building? Is there a limit to the amount of memory your model can use?
- What does the model need to do to effectively solve the business problem?
Based on these requirements, you can place constraints on the search process that your AutoML tool is using in order to get the right model for your business problem.
Don’t treat the best AutoML model as a black box
It is tempting to just assume that AutoML is perfect and you can treat the final model returned by AutoML as a black box and still trust it. The truth is, there is no “free lunch” in machine learning, even in automated machine learning.
https://towardsdatascience.com/what-no-free-lunch-really-means-in-machine-learning-85493215625d
Even your AutoML model has strengths and limitations and you should make an effort to understand what type of model the AutoML tool has selected. If the AutoML tool selected some variation of XGBoost as the optimal model, for example, you need to have at least a high-level understanding of how XGBoost works and what it’s limitations are as an algorithm.
Understanding how the AutoML model works also helps you understand inconsistencies and anomalies that occur during the performance monitoring part of the model deployment phase in the data science process. This idea leads us to the next point.
Always do a sanity check
As I mentioned earlier, you shouldn’t treat your AutoML model as a black box and trust it blindly. This is why you need to do some kind of a sanity check to make sure the predictions that your model is generating actually make sense. One way to do this is to use a framework for explainable machine learning such as LIME or SHAP to explain some of the predictions generated by your model. This allows you to determine if you can truly trust the decision-making process that your model is using. In my previous article on explainable machine learning, I provided specific examples showing how you can use LIME and SHAP to explain the reasoning behind your model’s predictions.
https://towardsdatascience.com/what-no-free-lunch-really-means-in-machine-learning-85493215625d
Another way to sanity-check your model is to monitor its performance during an initial deployment phase and check to see if it’s predictions on unseen real-world data are reasonable. If you find that your model is producing unreasonable or inaccurate predictions during this phase, you may have to go back to a previous phase in the data science process to fine-tune your model. This is why the TDSP is iterative and meant to be an agile approach to data science. Data science is can be viewed as a form of experimental science because models are like hypotheses or theories that may be revised as we receive new data from the real-world that highlights inconsistencies in them. By taking these extra steps to experiment with and test the model, you can have confidence in your AutoML model rather than blindly trusting it and running into unexpected issues down the road.
Summary
- AutoML is great, but it can’t solve all aspects of your machine learning business problems for you.
- Before you get started with AutoML, make sure you understand the business requirements of the problem you are trying to solve.
- Make sure you understand the limitations of the type of model selected by the AutoML tool you used.
- Resist the temptation to treat your AutoML model as a black box and make sure you do a sanity check before blindly trusting it.
Sources
- Microsoft Azure Team, What is the Team Data Science Process?, (2020), Team Data Science Process Documentation.