An introduction to the models that have revolutionized natural language processing in the last few years.

One innovation that has taken natural language processing to new heights in the last three years was the development of transformers. And no, I’m not talking about the giant robots that turn into cars in the famous science-fiction film series directed by Michael Bay.
Transformers are semi-supervised machine learning models that are primarily used with text data and have replaced recurrent neural networks in natural language processing tasks. The goal of this article is to explain how transformers work and to show you how you can use them in your own machine learning projects.
How Transformers Work
Transformers were originally introduced by researchers at Google in the 2017 NIPS paper Attention is All You Need. Transformers are designed to work on sequence data and will take an input sequence and use it to generate an output sequence one element at a time.
For example, a transformer could be used to translate a sentence in English into a sentence in French. In this case, a sentence is basically treated as a sequence of words. A transformer has two main segments, the first is an encoder that operates primarily on the input sequence and the second is a decoder that operates on the target output sequence during training and predicts the next item in the sequence. In a machine translation problem, for example, the transformer may take a sequence of words in English and iteratively predict the next French word in the proper translation until the sentence has been completely translated. The diagram below demonstrates how a transformer is put together, with the encoder on the left and the decoder on the right.

It looks like there’s a lot going on in the diagram above, so let’s take a look at each component separately. The parts of a transformer that are particularly important are the embeddings, the positional encoding block, and the multi-head attention blocks.
Input and Output Embedding
If you have ever worked with word embeddings using the Word2Vec algorithm, the input and output embeddings are basically just embedding layers. The embedding layer takes a sequence of words and learns a vector representation for each word.
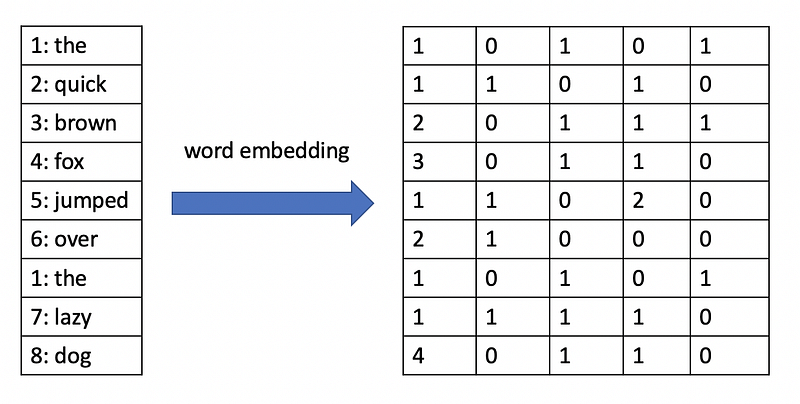
In the image above, a word embedding has been created for the sentence “the quick brown fox jumped over the lazy dog”. Notice how the sentence with nine words has been transformed into a 9 x 5 embedding matrix.
The Word2Vec algorithm uses a large sample of text as training data and learns word embeddings using one of two algorithms:
- Continuous bag of words (CBOW) — in this case, the algorithm tries to predict a center word in the middle of the sentence using the surrounding context words.
- Skip-gram model — in this case, the algorithm does the opposite of CBOW and predicts the distribution of context words from a center word.
Word2Vec uses a shallow neural network with just one hidden layer to make these predictions. The word vectors come from the weights learned in the hidden layer and are used to represent the semantic meaning of each word in relation to other words. The idea behind Word2Vec is that words with similar meanings will have similar embedding vectors. For a more comprehensive explanation of this algorithm, please see these lecture notes from Stanford’s NLP class.
What’s important to understand from this description is that the input and output embeddings both take a text document and produce an embedding matrix with an embedding vector for each word.
Positional Encoding
The positional encoding block applies a function to the embedding matrix that allows a neural network to understand the relative position of each word vector even if the matrix was shuffled. This might seem insignificant, but you will see why it’s important when I describe the attention blocks in detail.
The positional encoding blocks inject information about the position of each word vector by concatenating sine and cosine functions of different wavelengths/frequencies to these vectors as demonstrated in the equations below.
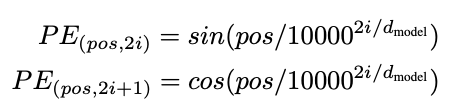
Given the equations below, if we consider an input with 10,000 possible positions, the positional encoding block will add sine and cosine values with wavelengths that increase geometrically from 2𝝅 to 10000*2𝝅. This allows us to mathematically represent the relative position of word vectors such that a neural network can learn to recognize differences in position.
Multi-Head Attention
The multi-head attention block is the main innovation behind transformers. The question that the attention block aims to answer is what parts of the text should the model focus on? This is exactly why it is called an attention block. Each attention block takes three input matrices:
- A query matrix, Q, of dimension n.
- A key matrix, K, of dimension n.
- And a value matrix, V, m.
This concept is best explained through a practical example. Let’s say the query matrix has values that represent a sentence in English such as “the quick brown fox jumped”. Let’s say that our goal is to translate this sentence into French. In this case, the transformer will have learned weights for individual English words in a key matrix and the query matrix will represent the actual input sentence. Computing the dot product of the query and key matrix is known as self-attention and will produce an output that looks something like this.
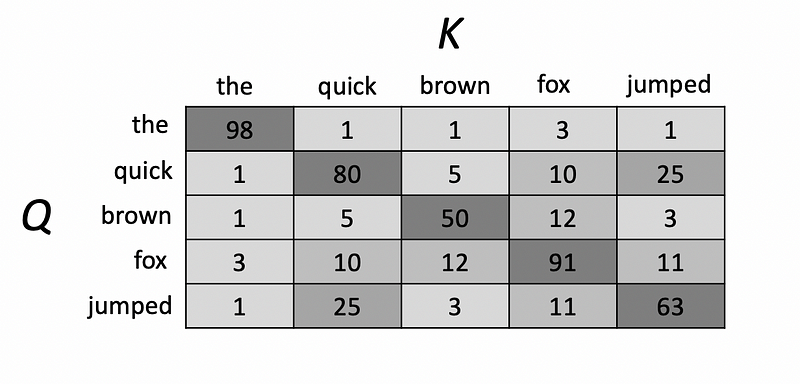
Note that the key matrix contains representations of each word and the dot product is essentially a matrix of similarity scores between the query matrix and the key matrix. These scores are later scaled by dividing the dot product matrix by the square root of the number of dimensions in the key and query matrices. A softmax activation function is applied to the scaled scores to convert them into probabilities. These probabilities are referred to as the attention weights, which are then multiplied by the value matrix to produce the final output of the attention block. The final output of the attention block is defined using the equation below:
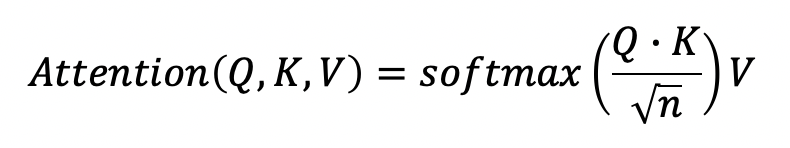
Note that n was previously defined as the number of dimensions in the query matrix (Q) and the key matrix (K). The key and value matrices are learned parameters while the query matrix is defined by the input word vectors. It is also important to note that the words of a sentence are passed into the transformer at the same time and the concept of a sequential order present in LSTMs is not that apparent with transformers. This is why the positional encoding blocks mentioned earlier are important. They allow attention block to understand the relative position of words in sentences.
A single attention block can tell a model to pay attention to something specific such as the tense in a sentence. Adding multiple attention blocks allows the model to pay attention to different linguistic elements such as part of speech, tense, nouns, verbs, and so on.
Add & Norm
This layer simply takes the outputs from the multi-head attention block, adds them together, and normalizes the result with layer normalization. If you have heard of batch normalization, layer normalization is similar but instead of normalizing the input features across the batch dimensions, it normalizes the inputs to a layer across all features.
Feed-Forward Layer
This layer needs very little explanation. It is simply a single fully-connected layer of a feed-forward neural network. The feed-forward layer operates on the output attention vectors and learns to recognize patterns within them.
Now that we have covered each of the building blocks of a transformer, we can see how they fit together in the encoder and decoder segments.
The Encoder
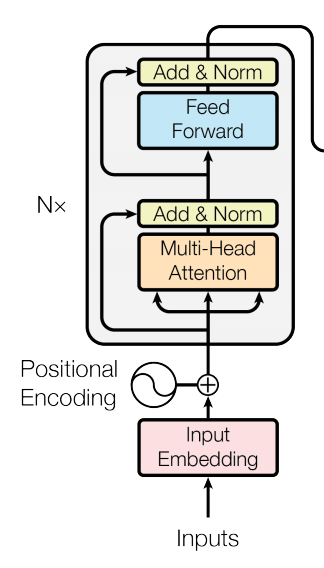
The encoder is the part of the transformer that chooses what parts of the input to focus on. The encoder can take a sentence such as “the quick brown fox jumped”, computes the embedding matrix, and then converts it into a series of attention vectors. The multi-head attention block initially produces these attention vectors, which are then added and normalized, passed into a fully-connected layer (Feed Forward in the diagram above), and normalized again before being passed over to the decoder.
The Decoder
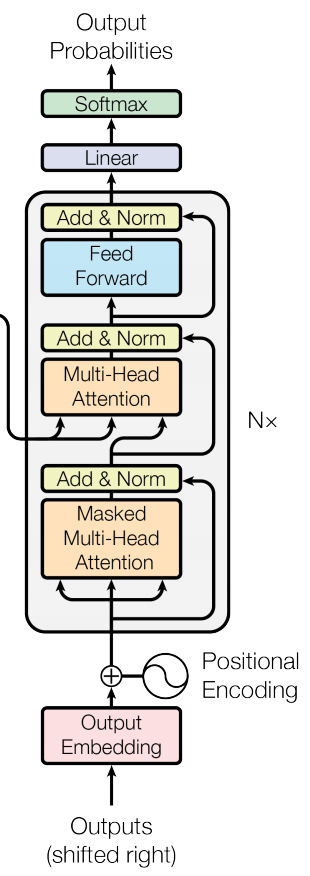
During training, the decoder operates directly on the target output sequence. As per our example, let’s assume the target output is the French translation of the English sentence “the quick brown fox jumped”, which translates to “le renard brun rapide a sauté” in French. In the decoder, separate embedding vectors are computed for each French word in the sentence, and the positional encoding is also applied in the form of sine and cosine functions.
However, a masked attention block is used, meaning that only the previous word in the French sentence is used and the other words are masked. This allows the transformer to learn to predict the next French word. The outputs of this masked attention block are added and normalized before being passed to another attention block that also receives the attention vectors produced by the encoder.
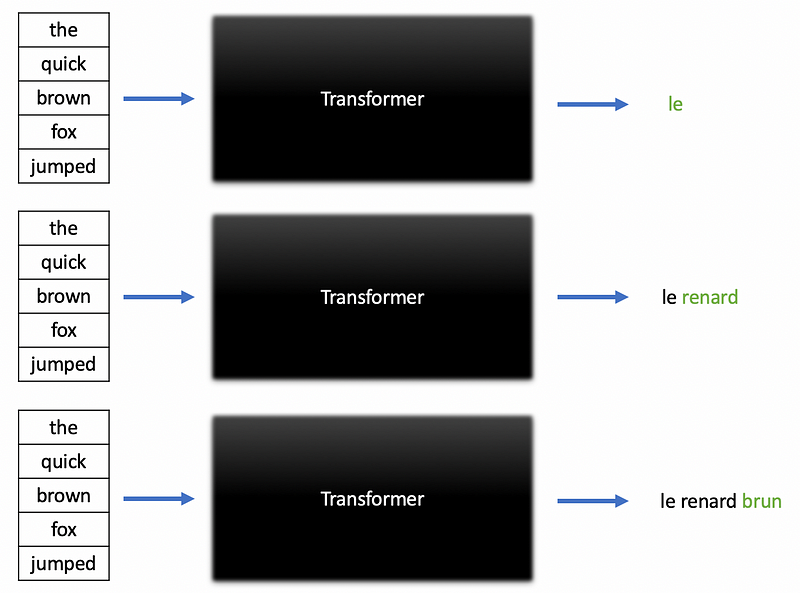
A feed-forward network receives the final attention vectors and uses them to produce a single vector with a dimension equal to the number of unique words in the model’s vocabulary. Applying the softmax activation function to this vector produces a set of probabilities corresponding to each word. In the context of our example, these probabilities predict the likelihood of each French word appearing next in the translation. This is how a transformer performs tasks such as machine translation and text generation. Just as demonstrated in the figure below, a transformer iteratively predicts the next word in a translated sentence when performing translation tasks.
Common Transformer Architectures
In the last few years, several architectures based on the basic transformer introduced in the 2017 paper have been developed and trained for complex natural language processing tasks. Some of the most common transformer models that were created recently are listed below:
How You Can Use Transformers with HuggingFace
Transformers are definitely useful and as of 2020, are considered state-of-the-art NLP models. But implementing them seems quite difficult for the average machine learning practitioner. Luckily, HuggingFace has implemented a Python package for transformers that is really easy to use. It is open-source and you can find it on GitHub.
To install the transformers package run the following pip command:
pip install transformers
Make sure to install the library in a virtual environment as per the instructions provided in the GitHub repository. This package allows you to not only use pre-trained state-of-the-art transformers such as BERT and GPT for standard tasks but also lets you finetune them for your own tasks. Consider some of the examples below.
Sentiment Analysis with Transformers
The transformers package from HuggingFace has a really simple interface provided through the pipeline module that makes it easy to use pre-trained transformers for standard tasks such as sentiment analysis. Consider the example below.
from transformers import pipeline
classifier = pipeline('sentiment-analysis')
classifier('Batman Begins is a great movie! Truly a classic!')
Running this code produces a dictionary indicating the sentiment of the text.
[{'label': 'POSITIVE', 'score': 0.9998838305473328}]
Question-Answering with Transformers
We can also use the pipeline module for answering questions given some context information as demonstrated in the example below.
from transformers import pipeline
question_answerer = pipeline('question-answering')
question_answerer({
'question': 'What is the name of my dog?',
'context': 'I have a dog named Sam. He likes to chase cats in the neighborhood.'})
Running the code produces the output shown below.
{'score': 0.9907370805740356, 'start': 19, 'end': 22, 'answer': 'Sam'}
Interestingly, the transformer not only gives us the answer to the question about the name of the dog but also tells us where we can find the answer in the context string.
Translation
In this article, I gave the example of translating English sentences to French in order to demonstrate how transformers work. The pipeline module, as expected, allows us to use transformer models to translate text from one language to another as demonstrated below.
from transformers import pipeline
translator = pipeline('translation_en_to_fr')
translator("The quick brown fox jumped.")
Running the code above produces the French translation shown below.
[{'translation_text': 'Le renard brun rapide saute.'}]
Text Summarization
We can also use transformers for text summarization. In the example below, I used the T5 transformer to summarize Winston Churchill’s famous “Never Give In” speech in 1941 during one of the darkest times in World War II.
from transformers import pipeline
summarizer = pipeline('summarization', model="t5-base", tokenizer="t5-base", framework="tf")
speech = open('./data/never_give_in.txt').read()
summarizer(speech, min_length=50, max_length=100)
Running the code above produces this concise and beautifully worded summary below.
[{'summary_text': 'a year ago, we stood all alone, and to many countries it seemed that our account was closed, we were finished and liquidated . today, we can be sure that we have only to persevere to conquer . do not let us speak of dark days; these are great days - the greatest days our country has ever lived .'}]
Finetuning Transformers for Text Classification
We can also fine-tune pre-trained transformers for text classification tasks using transfer learning. In one of my previous articles, I used recurrent convolutional neural networks for classifying fake news articles.
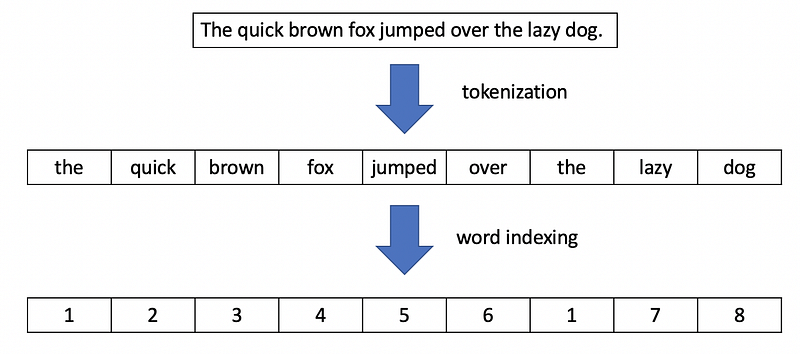
In the example below, I used a preprocessed version of the same fake news dataset to train a BERT transformer model to detect fake news. Fine-tuning models requires a few extra steps so the sample code I provided is understandable but a bit more complicated than the previous examples. We not only have to import the transformer model, but also a tokenizer that can transform a text document into a series of integer tokens corresponding to different words as demonstrated in the image below.
Please note that I ran the code below on a GPU instance in AWS SageMaker because the training process is computationally expensive. If you plan on running this code yourself, I would recommend using a GPU.
https://gist.github.com/AmolMavuduru/8fd051007b6b49d808bbc1b087c2d4af
There’s a lot going on in the code above so here’s an overview of the steps that I performed in the process of fine-tuning the BERT transformer:
- Loaded the pre-trained BERT transformer model and initialized it for binary classification problems.
- Loaded the BERT tokenizer for encoding the text data as a series of integer tokens corresponding to each word.
- Read the fake news dataset using pandas and split it into training and validation sets.
- Encoded the text for the training and validation data using the BERT tokenizer and used this data to create TensorFlow datasets for training and validation.
- Set the parameters for the model and trained it for a single epoch on the training dataset.
The code produced the following output after the training process was complete:
3238/3238 [==============================] - 3420s 1s/step - loss: 0.1627 - accuracy: 0.9368 - val_loss: 0.1179 - val_accuracy: 0.9581
<tensorflow.python.keras.callbacks.History at 0x7f12f39dc080>
The finetuned BERT model achieved a validation accuracy of 95.81 percent after just one training epoch, which is quite impressive. With more training epochs, it may achieve an even higher validation accuracy.
Summary
- Transformers are powerful deep learning models that can be used for a wide variety of natural language processing tasks.
- The transformers package provided by HuggingFace makes it very easy for developers to use state-of-the-art transformers for standard tasks such as sentiment analysis, question-answering, and text-summarization.
- You can also finetune pre-trained transformers for your own natural language processing tasks.
As usual, I have made the full code for this article available on GitHub.
Sources
- A. Vaswani, N. Shazeer, et. al, Attention Is All You Need, (2017), 31st Conference on Neural Information Processing Systems.
- F. Chaubard, M. Fang, et. al, Word Vectors I: Introduction, SVD and Word2Vec, (2019), CS224n: Natural Language Processing with Deep Learning lecture notes, Stanford University.
- J. Devlin, M. W. Chang, K. Lee, and K. Toutanova, BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding, (2018), arXiv.org.
- V. Sanh, L. Debut, J. Chaumond, and T. Wolf, DistilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter, (2019), arXiv.org.
- C. Raffel, N. Shazeer, et. al, Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer, (2019), arXiv.org.
- A. Radford, J.Wu, et. al, Language Models are Unsupervised Multitask Learners, (2019), OpenAI.