An introduction to a more sophisticated approach to topic modeling.

Topic modeling is a problem in natural language processing that has many real-world applications. Being able to discover topics within large sections of text helps us understand text data in greater detail.
For many years, Latent Dirichlet Allocation (LDA) has been the most commonly used algorithm for topic modeling. The algorithm was first introduced in 2003 and treats topics as probability distributions for the occurrence of different words. If you want to see an example of LDA in action, you should check out my article below where I performed LDA on a fake news classification dataset.
However, with the introduction of transformer models and embedding algorithms such as Doc2Vec, we can create much more sophisticated topic models that capture semantic similarities in words. In fact, an algorithm called Top2Vec makes it possible to build topic models using embedding vectors and clustering. In this article, I will demonstrate how you can use Top2Vec to perform unsupervised topic modeling using embedding vectors and clustering techniques.
How does Top2Vec work?
Top2Vec is an algorithm that detects topics present in the text and generates jointly embedded topic, document, and word vectors. At a high level, the algorithm performs the following steps to discover topics in a list of documents.
- Generate embedding vectors for documents and words.
- Perform dimensionality reduction on the vectors using an algorithm such as UMAP.
- Cluster the vectors using a clustering algorithm such as HDBSCAN.
- Assign topics to each cluster.
I have explained each step in detail below.
Generate embedding vectors for documents and words
An embedding vector is a vector that allows us to represent a word or text document in multi-dimensional space. The idea behind embedding vectors is that similar words or text documents will have similar vectors.
There are many algorithms for generating embedding vectors. Word2Vec and Doc2Vec are quite popular but in recent years, NLP developers and researchers have started using transformers to generate embedding vectors. If you’re interested in learning more about transformers, check out my article below.
Creating embedding vectors for each document allows us to treat each document as a point in multi-dimensional space. Top2Vec also creates jointly embedded word vectors, which allows us to determine topic keywords later.

Once we have a set of word and document vectors, we can move on to the next step.
Perform dimensionality reduction
After we have vectors for each document, the next natural step would be to divide them into clusters using a clustering algorithm. However, the vectors generated from the first step can have as many as 512 components depending on the embedding model that was used.
For this reason, it makes sense to perform some kind of dimensionality reduction algorithm to reduce the number of dimensions in the data. Top2Vec uses an algorithm called UMAP (Uniform Manifold Approximation and Projection) to generate lower-dimensional embedding vectors for each document.
Cluster the vectors
Top2Vec uses HDBSCAN, a hierarchical density-based clustering algorithm, to find dense areas of documents. HDBSCAN is basically just an extension of the DBSCAN algorithm that converts it into a hierarchical clustering algorithm. Using HDBSCAN for topic modeling makes sense because larger topics can consist of several subtopics.
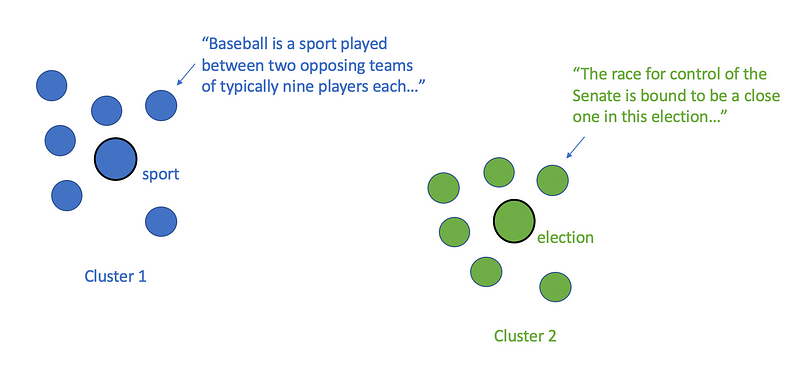
Assign topics to each cluster
Once we have clusters for each document, we can simply treat each cluster of documents as a separate topic in the topic model. Each topic can be represented as a topic vector that is essentially just the centroid (average point) of the original documents belonging to that topic cluster. In order to label the topic using a set of keywords, we can compute the n-closest words to the topic centroid vector.
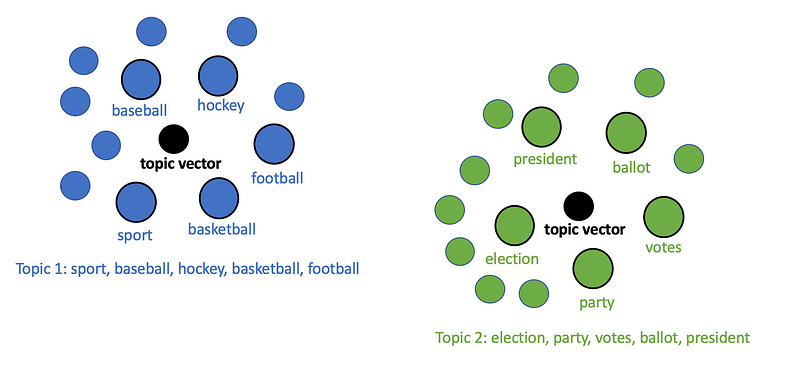
Once we have keywords for each topic, the algorithm’s job is done, and it’s up to us as humans to interpret what these topics really mean. While Top2Vec is much more complex than the standard LDA approach to topic modeling, it may be able to give us better results since the embedding vectors for words and documents can effectively capture the meaning of words and phrases.
Installing Top2Vec
You can install Top2Vec using pip with the following command:
pip install top2vecYou can also install Top2Vec with additional options as demonstrated in the README document in the Top2Vec GitHub repository.
In order to get Top2Vec installed with the pre-trained universal sentence encoders required to follow along with this tutorial, you should run the following command.
pip install top2vec[sentence_encoders]
Top2Vec tutorial
In this tutorial, I will demonstrate how to use Top2Vec to discover topics in the 20 newsgroups text dataset. This dataset contains roughly 18000 newsgroups posts on 20 topics. You can access the full code for this tutorial on GitHub.
Import Libraries
import numpy as np
import pandas as pd
from top2vec import Top2Vec
Reading the Data
For this tutorial, I will be using the 20 newsgroups text dataset. This dataset contains roughly 18000 newsgroups posts on 20 topics. We can download the dataset through Scikit-learn as demonstrated below.
from sklearn.datasets import fetch_20newsgroups
newsgroups = fetch_20newsgroups(subset='all', remove=('headers', 'footers', 'quotes'))
Training a Top2Vec Model
Training a Top2Vec model is very easy and requires only one line of code as demonstrated below.
from top2vec import Top2Vec
model = Top2Vec(articles_df['content'].values, embedding_model='universal-sentence-encoder')
Note that I used the universal sentence encoder embedding model above. You can use this model if you installed Top2Vec with the sentence encoders option. Otherwise, simply remove this argument and the model will be trained with Doc2Vec embeddings by default.
Viewing the Number of Topics
Once a Top2Vec model has been trained on the data, we can use the model object to get information about the topics that were extracted. For example, we can view the number of topics that were discovered using the get_num_topics function as demonstrated below.
model.get_num_topics()
Running the code above produces the following output.
100
Getting Keywords for each Topic
The Top2Vec model has an attribute called topic_words that is basically just a Numpy array with lists of words for each topic.
model.topic_words
Running the code above in a Jupyter notebook cell produces the following output.
array([['recchi', 'potvin', 'nyr', ..., 'pittsburgh', 'binghamton',
'pitt'],
['diagnosed', 'symptoms', 'diagnosis', ..., 'mfm', 'affected',
'admitted'],
['spacecraft', 'jpl', 'orbiter', ..., 'scientist', 'convention',
'comet'],
...,
['liefeld', 'wolverine', 'comics', ..., 'requests', 'tickets',
'lemieux'],
['vice', 'pacific', 'bay', ..., 'projects', 'chapter', 'caps'],
['armenians', 'ankara', 'armenian', ..., 'discussed',
'azerbaijani', 'whom']], dtype='<U15')
If we want to see the words for a specific topic, we can simply index this array as demonstrated below.
model.topic_words[0]
The code above gives us the following list of words for topic 0.
array(['recchi', 'potvin', 'nyr', 'nyi', 'lemieux', 'lindros', 'nhl',
'phillies', 'defenseman', 'mets', 'ahl', 'jagr', 'bruins',
'sabres', 'cubs', 'gretzky', 'alomar', 'pitchers', 'pitching',
'clemens', 'canucks', 'inning', 'henrik', 'innings', 'yankees',
'oilers', 'utica', 'islanders', 'boswell', 'braves', 'hockey',
'rangers', 'leafs', 'flyers', 'sox', 'playoffs', 'wpg', 'baseball',
'dodgers', 'espn', 'goalie', 'fuhr', 'playoff', 'ulf', 'hawks',
'batting', 'tampa', 'pittsburgh', 'binghamton', 'pitt'],
dtype='<U15')
As we can see, this topic seems to be mostly about sports, particularly baseball and hockey because we see the names of popular baseball teams along with the last names of hockey players.
Creating Topic Word Clouds
We can easily generate word clouds for topics in order to get a better understanding of the frequency of keywords within a topic.
model.generate_topic_wordcloud(0)
Running the code above produces the word cloud below.

The word cloud above is useful because it lets us visually understand the relative frequency of different words with the topic. We can see that words such as “Phillies” and “Lemieux” appear more often than words such as “playoff” or “Tampa”.
Accessing Topic Vectors
The topic_vectors attribute allows us to access the topic vectors for each topic as demonstrated below.
model.topic_vectors
As we can see in the output below, the topic vectors for a Top2Vec model are stored as a two-dimensional Numpy array where each row corresponds to a specific topic vector.
array([[-9.1372393e-03, -8.8540517e-02, -5.1944017e-02, ...,
2.0455582e-02, -1.1964893e-01, -1.1116098e-04],
[-4.0708046e-02, -2.6885601e-02, 2.2835255e-02, ...,
7.2831921e-02, -6.1708521e-02, -5.2916467e-02],
[-3.2222651e-02, -4.7691587e-02, -2.9298926e-02, ...,
4.8001394e-02, -4.6445496e-02, -3.5007432e-02],
...,
[-4.3788709e-02, -6.5007553e-02, 5.3533200e-02, ...,
2.7984662e-02, 6.5978311e-02, -4.4375043e-02],
[ 1.2126865e-02, -4.5126071e-03, -4.6988029e-02, ...,
3.7431438e-02, -1.2432544e-02, -5.3018846e-02],
[-5.2520853e-02, 4.9585234e-02, 5.9694829e-03, ...,
4.1887209e-02, -2.1055080e-02, -5.4151181e-02]], dtype=float32)
If we want to access the vector for any topic, for example, we can simply index the Numpy array based on the topic number we are looking for.
Using the Model’s Embedding Function
We can also use the embedding model used by the Top2Vec model to generate document embeddings for any section of text as demonstrated below. Note that this is not possible if you did not specify an embedding model when training the Top2Vec model.
embedding_vector = model.embed(["This is a fake news article."])
embedding_vector.shape
Running the function above produces the following output.
TensorShape([1, 512])
Based on the output above, we can see that the embedding model transformed the text into a 512-dimensional vector in the form of a Python Tensor object.
Searching for Topics Using Keywords
We can search for topics using keywords as demonstrated below. Note that the function returns lists of topic keywords, word scores, topic scores, and topic numbers for each topic that is found from the search.
topic_words, word_scores, topic_scores, topic_nums = model.search_topics(keywords=["politics"], num_topics=3)
We can take a look at the topic words and topic scores to see what topics were returned from the search.
topic_words, topic_scores
The code above produces the following output in Jupyter.
([array(['clinton', 'bush', 'president', 'reagan', 'democratic',
'republicans', 'elected', 'congress', 'wiretap', 'administration',
'election', 'johnson', 'politically', 'politicians', 'politics',
'political', 'executive', 'senate', 'bill', 'constitutional',
'democracy', 'lib', 'government', 'gov', 'iraq', 'corrupt',
'convention', 'rockefeller', 'nist', 'ford', 'grant',
'libertarian', 'nuy', 'govt', 'feds', 'libertarians', 'decades',
'recall', 'ws', 'bureau', 'bullshit', 'nsa', 'stephanopoulos',
'weren', 'liar', 'koresh', 'affairs', 'barry', 'conservative',
'secretary'], dtype='<U15'),
array(['um', 'ci', 'oo', 'll', 'ye', 'hmm', 'un', 'uh', 'y_', 'wt', 'on',
'uu', 'actually', 'an', 'eh', 'way', 'des', 'er', 'se', 'not',
'has', 'huh', 'of', 'ya', 'so', 'it', 'in', 'le', 'upon', 'hm',
'one', 'is', 'es', 'ne', 'at', 'what', 'no', 'au', 'est', 'shut',
'mm', 'got', 'dont', 'lo', 'tu', 'en', 'the', 'have', 'am',
'there'], dtype='<U15'),
array(['libertarian', 'libertarians', 'govt', 'liberties', 'democracy',
'democratic', 'government', 'conservative', 'gov', 'republicans',
'governments', 'liberty', 'constitutional', 'opposed', 'communist',
'politically', 'advocate', 'citizens', 'premise', 'opposition',
'patents', 'fascist', 'opposing', 'compromise', 'feds', 'liberal',
'politicians', 'independent', 'reform', 'johnson', 'philosophy',
'ron', 'citizen', 'aclu', 'politics', 'frankly', 'xt', 'defend',
'political', 'regulated', 'militia', 'republic', 'radical',
'against', 'amendment', 'unified', 'argument', 'revolution',
'senate', 'obey'], dtype='<U15')],
array([0.23019153, 0.21416718, 0.19618901]))
We can see that the topics are also ranked by topic score. The topics with the highest similarity scores are shown first in the first list above.
Searching for Documents by Topic
We can easily find documents that belong to specific topics with the search_documents_by_topic function. This function requires both a topic number and the number of documents that we want to retrieve.
model.search_documents_by_topic(0, num_docs=1)
Running the function above produces the following output.
(array(['\nI think this guy is going to be just a little bit disappointed. Lemieux\ntwo, Tocchet, Mullen, Tippett, and Jagr. I buzzed my friend because I forgot\nwho had scored Mullen\'s goal. I said, "Who scored? Lemieux two, Tocchet,\nTippett, Jagr." The funny part was I said the "Jagr" part non-chalantly as\nhe was in the process of scoring while I was asking this question!!! :-)\n\nAll in all ABC\'s coverage wasn\'t bad. On a scale of 1-10, I give it about\nan 8. How were the games in the Chi/St. Louis/LA area???\n\n\nThat\'s stupid!!! I\'d complain to the television network! If I were to even\nsee a Pirates game on instead of a Penguins game at this time of the year, I\nand many other Pittsburghers would surely raise hell!!!\n\n\nTexas is off to a good start, they may pull it out this year. Whoops! That\nbelongs in rec.sport.baseball!!!'],
dtype=object),
array([0.75086796], dtype=float32),
array([12405]))
We can see that the article above is definitely about baseball, which matches our interpretation of the first topic.
Reducing the Number of Topics
Sometimes the Top2Vec model will discover many small topics and it is difficult to work with so many different topics. Fortunately, Top2Vec allows us to perform hierarchical topic reduction, which iteratively merges similar topics until we have reached the desired number of topics. We can reduce the number of topics in the model from 100 topics to only 20 topics as demonstrated in the code below.
topic_mapping = model.hierarchical_topic_reduction(num_topics=20)
The topic mapping that the function returns is a nested list that explains which topics have been merged together to form the 20 larger topics.
If we want to look at the original topics within topic 1 we can run the following code in Jupyter.
topic_mapping[1]
The code above produces the following list of merged topic numbers.
[52, 61, 75, 13, 37, 72, 14, 21, 19, 74, 65, 15]
Working with this mapping, however, can be a bit tedious so Top2Vec allows us to access information for the new topics with new attributes. For example, we can access the new topic keywords with the topic_words_reduced attribute.
model.topic_words_reduced[1]
Running the code above gives us the following updated list of keywords for topic 1:
array(['irq', 'mhz', 'processor', 'sgi', 'motherboard', 'risc',
'processors', 'ati', 'dma', 'scsi', 'cmos', 'powerbook', 'vms',
'vga', 'cpu', 'packard', 'bsd', 'baud', 'maxtor', 'ansi',
'hardware', 'ieee', 'xt', 'ibm', 'computer', 'workstation', 'vesa',
'printers', 'deskjet', 'msdos', 'modems', 'intel', 'printer',
'linux', 'floppies', 'computing', 'implementations',
'workstations', 'hp', 'macs', 'monitor', 'vram', 'unix', 'telnet',
'bios', 'pcs', 'specs', 'oscillator', 'cdrom', 'pc'], dtype='<U15')
Based on the keywords above, we can see that this topic seems to be mostly about computer hardware.
For more details about the functions that are available in Top2Vec, please check out the Top2Vec GitHub repository. I hope you found this tutorial to be useful.
Summary
Top2Vec is a recently developed topic modeling algorithm that may replace LDA in the near future. Unlike LDA, Top2Vec generates jointly embedded word and document vectors and clusters these vectors in order to find topics within text data. The open-source Top2Vec library is also very easy to use and allows developers to train sophisticated topic models in just one line of code.
As usual, you can find the full code for this article on GitHub.
Join my Mailing List
Do you want to get better at data science and machine learning? Do you want to stay up to date with the latest libraries, developments, and research in the data science and machine learning community?
Join my mailing list to get updates on my data science content. You’ll also get my free Step-By-Step Guide to Solving Machine Learning Problems when you sign up!
And while you’re at it, consider joining the Medium community to read articles from thousands of other writers as well.
Sources
- D. M. Blei, A. Y. Ng, M. I. Jordan, Latent Dirichlet Allocation, (2003), Journal of Machine Learning Research 3.
- D. Angelov, Top2Vec: Distributed Representations of Topics, (2020), arXiv.org.
- L. McInnes, J. Healy, and J. Melville, UMAP: Uniform Manifold Approximation and Projection for Dimension Reduction, (2020), arXiv.org.
- C. Malzer and M. Baum, A Hybrid Approach To Hierarchical Density-based Cluster Selection, (2021), arXiv.org.