Using Spotify’s data to generate music recommendations.

Have you ever wondered how Spotify recommends songs and playlists based on your listening history? Do you wonder how Spotify manages to find songs that sound similar to the ones you’ve already listened to?
Interestingly, Spotify has a web API that developers can use to retrieve audio features and metadata about songs such as the song’s popularity, tempo, loudness, key, and the year in which it was released. We can use this data to build music recommendation systems that recommend songs to users based on both the audio features and the metadata of the songs that they have listened to.
In this article, I will demonstrate how I used a Spotify song dataset and Spotipy, a Python client for Spotify, to build a content-based music recommendation system.
Installing Spotipy
Spotipy is a Python client for the Spotify Web API that makes it easy for developers to fetch data and query Spotify’s catalog for songs. In this project, I used Spotipy to fetch data for songs that did not exist in the original Spotify Song Dataset that I accessed from Kaggle. You can install Spotipy with pip using the command below.
pip install spotipy
After installing Spotipy, you will need to create an app on the Spotify Developer’s page and save your Client ID and secret key.
Import Libraries
In the code below, I imported Spotipy and some other basic libraries for data manipulation and visualization. You can find the full code for this project on GitHub.
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import spotipy
import os
%matplotlib inline
Reading the Data
In order to build a music recommendation system, I used the Spotify Dataset, which is publicly available on Kaggle and contains metadata and audio features for over 170,000 different songs. I used three data files from this dataset. The first one contains data for individual songs while the next two files contain the data grouped the genres and years in which the songs were released.
spotify_data = pd.read_csv('./data/data.csv.zip')
genre_data = pd.read_csv('./data/data_by_genres.csv')
data_by_year = pd.read_csv('./data/data_by_year.csv')
I have included the column metadata below that was generated by calling the Pandas info function for each data frame.
spotify_data
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 170653 entries, 0 to 170652
Data columns (total 19 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 valence 170653 non-null float64
1 year 170653 non-null int64
2 acousticness 170653 non-null float64
3 artists 170653 non-null object
4 danceability 170653 non-null float64
5 duration_ms 170653 non-null int64
6 energy 170653 non-null float64
7 explicit 170653 non-null int64
8 id 170653 non-null object
9 instrumentalness 170653 non-null float64
10 key 170653 non-null int64
11 liveness 170653 non-null float64
12 loudness 170653 non-null float64
13 mode 170653 non-null int64
14 name 170653 non-null object
15 popularity 170653 non-null int64
16 release_date 170653 non-null object
17 speechiness 170653 non-null float64
18 tempo 170653 non-null float64
dtypes: float64(9), int64(6), object(4)
memory usage: 24.7+ MB
genre_data
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 2973 entries, 0 to 2972
Data columns (total 14 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 mode 2973 non-null int64
1 genres 2973 non-null object
2 acousticness 2973 non-null float64
3 danceability 2973 non-null float64
4 duration_ms 2973 non-null float64
5 energy 2973 non-null float64
6 instrumentalness 2973 non-null float64
7 liveness 2973 non-null float64
8 loudness 2973 non-null float64
9 speechiness 2973 non-null float64
10 tempo 2973 non-null float64
11 valence 2973 non-null float64
12 popularity 2973 non-null float64
13 key 2973 non-null int64
dtypes: float64(11), int64(2), object(1)
memory usage: 325.3+ KB
data_by_year
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 2973 entries, 0 to 2972
Data columns (total 14 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 mode 2973 non-null int64
1 genres 2973 non-null object
2 acousticness 2973 non-null float64
3 danceability 2973 non-null float64
4 duration_ms 2973 non-null float64
5 energy 2973 non-null float64
6 instrumentalness 2973 non-null float64
7 liveness 2973 non-null float64
8 loudness 2973 non-null float64
9 speechiness 2973 non-null float64
10 tempo 2973 non-null float64
11 valence 2973 non-null float64
12 popularity 2973 non-null float64
13 key 2973 non-null int64
dtypes: float64(11), int64(2), object(1)
memory usage: 325.3+ KBExploratory Data Analysis
Based on the column descriptions above, we can see that each dataframe has information about the audio features such as the danceability and loudness of different songs, that have also been aggregated across genres and specific years.
Exploratory Data Analysis
This dataset is extremely useful and can be used for a wide range of tasks. Before building a recommendation system, I decided to create some visualizations to better understand the data and the trends in music over the last 100 years.
Music Over Time
Using the data grouped by year, we can understand how the overall sound of music has changed from 1921 to 2020. In the code below, I used Plotly to visualize the values of different audio features for songs over the past 100 years.
import plotly.express as px
sound_features = ['acousticness', 'danceability', 'energy', 'instrumentalness', 'liveness', 'valence']
fig = px.line(data_by_year, x='year', y=sound_features)
fig.show()
https://datapane.com/u/amolmavuduru/reports/music-over-time
Based on the plot above, we can see that music has transitioned from the more acoustic and instrumental sound of the early 1900s to the more danceable and energetic sound of the 2000s. The majority of the tracks from the 1920s were likely instrumental pieces from classical and jazz genres. The music of the 2000s sounds very different due to the advent of computers and advanced audio engineering technology that allows us to create electronic music with a wide range of effects and beats.
We can also take a look at how the average tempo or speed of music has changed over the years. The drastic shift in sound towards electronic music is supported by the graph produced by the code below as well.
fig = px.line(data_by_year, x='year', y='tempo')
fig.show()
https://datapane.com/u/amolmavuduru/reports/music-tempo-over-time/
Based on the graph above, we can clearly see that music has gotten significantly faster over the last century. This trend is not only the result of new genres in the 1960s such as psychedelic rock but also advancements in audio engineering technology.
Characteristics of Different Genres
This dataset contains the audio features for different songs along with the audio features for different genres. We can use this information to compare different genres and understand their unique differences in sound. In the code below, I selected the ten most popular genres from the dataset and visualized audio features for each of them.
top10_genres = genre_data.nlargest(10, 'popularity')
fig = px.bar(top10_genres, x='genres', y=['valence', 'energy', 'danceability', 'acousticness'], barmode='group')
fig.show()
https://datapane.com/u/amolmavuduru/reports/sound-of-different-genres
Many of the genres above, such as Chinese electropop are extremely specific and likely belong to one or more broad genres such as pop or electronic music. We can take these highly specific genres and understand how similar they are to other genres by clustering them based on their audio features.
Clustering Genres with K-Means
In the code below, I used the famous and simple K-means clustering algorithm to divide the over 2,900 genres in this dataset into ten clusters based on the numerical audio features of each genre.
from sklearn.cluster import KMeans
from sklearn.preprocessing import StandardScaler
from sklearn.pipeline import Pipeline
cluster_pipeline = Pipeline([('scaler', StandardScaler()), ('kmeans', KMeans(n_clusters=10, n_jobs=-1))])
X = genre_data.select_dtypes(np.number)
cluster_pipeline.fit(X)
genre_data['cluster'] = cluster_pipeline.predict(X)
Now that the genres have been assigned to clusters, we can take this analysis a step further by visualizing the clusters in a two-dimensional space.
Visualizing the Genre Clusters with t-SNE
There are many audio features for each genre and it is difficult to visualize clusters in a high-dimensional space. However, we can use a dimensionality reduction technique known as t-Distributed Stochastic Neighbor Embedding to compress the data into a two-dimensional space as demonstrated in the code below.
from sklearn.manifold import TSNE
tsne_pipeline = Pipeline([('scaler', StandardScaler()), ('tsne', TSNE(n_components=2, verbose=2))])
genre_embedding = tsne_pipeline.fit_transform(X)
projection = pd.DataFrame(columns=['x', 'y'], data=genre_embedding)
projection['genres'] = genre_data['genres']
projection['cluster'] = genre_data['cluster']
Now, we can easily visualize the genre clusters in a two-dimensional coordinate plane by using Plotly’s scatter function.
import plotly.express as px
fig = px.scatter(
projection, x='x', y='y', color='cluster', hover_data=['x', 'y', 'genres'])
fig.show()
https://datapane.com/u/amolmavuduru/reports/clustering-genres/
Clustering Songs with K-Means
We can also cluster the songs using K-means as demonstrated below in order to understand how to build a better recommendation system.
song_cluster_pipeline = Pipeline([('scaler', StandardScaler()),
('kmeans', KMeans(n_clusters=20,
verbose=2, n_jobs=4))],verbose=True)
X = spotify_data.select_dtypes(np.number)
number_cols = list(X.columns)
song_cluster_pipeline.fit(X)
song_cluster_labels = song_cluster_pipeline.predict(X)
spotify_data['cluster_label'] = song_cluster_labels
Visualizing the Song Clusters with PCA
The song data frame is much larger than the genre data frame so I decided to use PCA for dimensionality reduction rather than t-SNE because it runs significantly faster.
from sklearn.decomposition import PCA
pca_pipeline = Pipeline([('scaler', StandardScaler()), ('PCA', PCA(n_components=2))])
song_embedding = pca_pipeline.fit_transform(X)
projection = pd.DataFrame(columns=['x', 'y'], data=song_embedding)
projection['title'] = spotify_data['name']
projection['cluster'] = spotify_data['cluster_label']
Now, we can visualize the song cluster in a two-dimensional space using the code below.
import plotly.express as px
fig = px.scatter(projection, x='x', y='y', color='cluster', hover_data=['x', 'y', 'title'])
fig.show()
https://datapane.com/u/amolmavuduru/reports/clustering-songs
The plot above is interactive, so you can see the title of each song when you hover over the points. If you spend some time exploring the plot above you’ll find that similar songs tend to be located close to each other and songs within clusters tend to be at least somewhat similar. This observation is the key idea behind the content-based recommendation system that I created in the next section.
Building a Content-Based Recommender System
Based on the analysis and visualizations in the previous section, it’s clear that similar genres tend to have data points that are located close to each other while similar types of songs are also clustered together.
At a practical level, this observation makes perfect sense. Similar genres will sound similar and will come from similar time periods while the same can be said for songs within those genres. We can use this idea to build a recommendation system by taking the data points of the songs a user has listened to and recommending songs corresponding to nearby data points.
Finding songs that are not in the dataset
Before we build this recommendation system, we need to be able to accommodate songs that don’t exist in the original Spotify Songs Dataset. The find_song function that I defined below fetches the data for any song from Spotify’s catalog given the song’s name and release year. The results are returned as a Pandas Dataframe with the data fields present in the original dataset that I downloaded from Kaggle.
https://gist.github.com/AmolMavuduru/5507896df1d3befa3596cc92a6850a85
For detailed examples on how to use Spotipy, please refer to the documentation page here.
Generating song recommendations
Now we can finally build the music recommendation system! The recommendation algorithm I used is pretty simple and follows three steps:
- Compute the average vector of the audio and metadata features for each song the user has listened to.
- Find the n-closest data points in the dataset (excluding the points from the songs in the user’s listening history) to this average vector.
- Take these n points and recommend the songs corresponding to them
This algorithm follows a common approach that is used in content-based recommender systems and is generalizable because we can mathematically define the term closest with a wide range of distance metrics ranging from the classic Euclidean distance to the cosine distance. For the purpose of this project, I used the cosine distance, which is defined below for two vectors u and v.
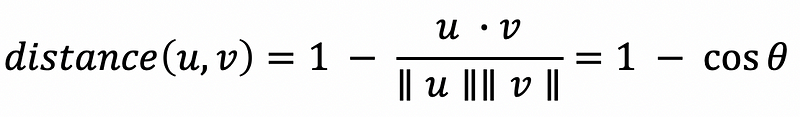
In other words, the cosine distance is one minus the cosine similarity — the cosine of the angle between the two vectors. The cosine distance is commonly used in recommender systems and can work well even when the vectors being used have different magnitudes. If the vectors for two songs are parallel, the angle between them will be zero, meaning the cosine distance between them will also be zero because the cosine of zero is 1.
The functions that I have defined below implement this simple algorithm with the help of Scipy’s cdist function for finding the distances between two pairs of collections of points.
https://gist.github.com/AmolMavuduru/9eb1b185b70a0d7432a761e57a60cf28
The logic behind the algorithm sounds convincing but does this recommender system really work? The only way to find out is by testing it with practical examples.
Let’s say that we want to recommend music for someone who listens to 1990s grunge, specifically songs by Nirvana. We can use the recommend_songs function to specify their listening history and generate recommendations as shown below.
recommend_songs([{'name': 'Come As You Are', 'year':1991},
{'name': 'Smells Like Teen Spirit', 'year': 1991},
{'name': 'Lithium', 'year': 1992},
{'name': 'All Apologies', 'year': 1993},
{'name': 'Stay Away', 'year': 1993}], spotify_data)
Running this function produces the list of songs below.
[{'name': 'Life is a Highway - From "Cars"',
'year': 2009,
'artists': "['Rascal Flatts']"},
{'name': 'Of Wolf And Man', 'year': 1991, 'artists': "['Metallica']"},
{'name': 'Somebody Like You', 'year': 2002, 'artists': "['Keith Urban']"},
{'name': 'Kayleigh', 'year': 1992, 'artists': "['Marillion']"},
{'name': 'Little Secrets', 'year': 2009, 'artists': "['Passion Pit']"},
{'name': 'No Excuses', 'year': 1994, 'artists': "['Alice In Chains']"},
{'name': 'Corazón Mágico', 'year': 1995, 'artists': "['Los Fugitivos']"},
{'name': 'If Today Was Your Last Day',
'year': 2008,
'artists': "['Nickelback']"},
{'name': "Let's Get Rocked", 'year': 1992, 'artists': "['Def Leppard']"},
{'name': "Breakfast At Tiffany's",
'year': 1995,
'artists': "['Deep Blue Something']"}]
As we can see from the list above, the recommendation algorithm produced a list of rock songs from the 1990s and 2000s. Bands in the list such as Metallica, Alice in Chains, and Nickelback are similar to Nirvana. The top song on the list, “Life is a Highway” is not a grunge song, but the rhythm of the guitar riff actually sounds similar to Nirvana’s “Smells Like Teen Spirit” if you listen closely.
What if we wanted to do the same for someone who listens to Michael Jackson songs?
recommend_songs([{'name':'Beat It', 'year': 1982},
{'name': 'Billie Jean', 'year': 1988},
{'name': 'Thriller', 'year': 1982}], spotify_data)
The recommendation function gives us the output below.
[{'name': 'Hot Legs', 'year': 1977, 'artists': "['Rod Stewart']"},
{'name': 'Thriller - 2003 Edit',
'year': 2003,
'artists': "['Michael Jackson']"},
{'name': "I Didn't Mean To Turn You On",
'year': 1984,
'artists': "['Cherrelle']"},
{'name': 'Stars On 45 - Original Single Version',
'year': 1981,
'artists': "['Stars On 45']"},
{'name': "Stars On '89 Remix - Radio Version",
'year': 1984,
'artists': "['Stars On 45']"},
{'name': 'Take Me to the River - Live',
'year': 1984,
'artists': "['Talking Heads']"},
{'name': 'Nothing Can Stop Us', 'year': 1992, 'artists': "['Saint Etienne']"}]
The top song on the list is by Rod Stewart, who like Michael Jackson, rose to fame in the 1980s. The list also contains a 2003 edit of Michael Jackson’s Thriller, which makes sense given that the user has already heard the original 1982 version of this song. The list also includes pop and rock songs from 1980s groups such as Stars On 45 and Talking Heads.
There are many more examples that we could work with, but these examples should be enough to demonstrate how the recommender system produces song recommendations. For a more complete set of examples, check out the GitHub repository for this project. Feel free to create your own playlists with this code!
Summary
Spotify keeps track of metadata and audio features for songs that we can use to build music recommendation systems. In this article, I demonstrated how you can use this data to build a simple content-based music recommender system with the cosine distance metric. As usual, you can find the full code for this project on GitHub.
If you enjoyed this article and want to learn more about recommender systems, check out some of my previous articles listed below.
https://towardsdatascience.com/how-to-build-powerful-deep-recommender-systems-using-spotlight-ec11198c173chttps://towardsdatascience.com/how-to-build-powerful-deep-recommender-systems-using-spotlight-ec11198c173c
Join My Mailing List
Do you want to get better at data science and machine learning? Do you want to stay up to date with the latest libraries, developments, and research in the data science and machine learning community?
Join my mailing list to get updates on my data science content. You’ll also get my free Step-By-Step Guide to Solving Machine Learning Problems when you sign up!
Sources
- Y. E. Ay, Spotify Dataset 1921–2020, 160k+ Tracks, (2020), Kaggle.
- L. van der Maaten and G. Hinton, Visualizing Data using t-SNE, (2008), Journal of Machine Learning Research.
- P. Virtanen et. al, SciPy 1.0: Fundamental Algorithms for Scientific Computing in Python, (2020), Nature Methods.