Using this Python library to build a book recommendation system.

If you’ve ever worked on a data science project, you probably have a default library that you use for standard tasks. Most people will probably use Pandas for data manipulation, Scikit-learn for general-purpose machine learning applications, and TensorFlow or PyTorch for deep learning. But what would you use to build a recommender system? This is where Surprise comes into play.
Surprise is an open-source Python library that makes it easy for developers to build recommender systems with explicit rating data. In this article, I will show you how you can use Surprise to build a book recommendation system using the goodbooks-10k dataset available on Kaggle under the CC BY-SA 4.0 license.
Installation
You can install Surprise with pip using the following command.
pip install scikit-surprise
If you would prefer to use Anaconda for package management, you can use the following command to install Surprise with Anaconda.
conda install -c conda-forge scikit-surpriseIf you want to install the latest version of the library directly from GitHub, you should use the following commands (you will need Numpy and Cython).
pip install numpy cython
git clone https://github.com/NicolasHug/surprise.git
cd surprise
python setup.py installBuilding a Book Recommendation System
You can find the entire code for this practical example on GitHub.
Import Libraries
To get started, I just imported some basic libraries for data manipulation and visualization.
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
%matplotlib inline
Read the Dataset
I used two CSV files from the goodbooks-10k dataset available on Kaggle. The first one contains rating data for 10,000 books rated by over 53,000 users. The second file contains the metadata (title, author, ISBN, etc.) for each of the 10,000 books.
ratings_data = pd.read_csv('./data/ratings.csv.zip')
books_metadata = pd.read_csv('./data/books.csv.zip')
ratings_data.head(10)
Create a Surprise Dataset
In order to train recommender systems with Surprise, we need to create a Dataset object. A Surprise Dataset object is a dataset that contains the following fields in this order:
- The user IDs
- The item IDs (in this case the IDs for each book)
- The corresponding rating (usually on a scale such as 1–5)
from surprise import Dataset
from surprise import Reader
reader = Reader(rating_scale=(1, 5))
data = Dataset.load_from_df(ratings_data[['user_id', 'book_id', 'rating']], reader)
Training and Cross-Validating a Simple SVD Model
We can train and cross-validate a model that performs SVD (singular value decomposition) in order to build a recommendation system in just a few lines of code. SVD is a popular matrix factorization algorithm that can be used for recommender systems.
Recommender systems that use matrix factorization generally follow a pattern where a matrix of ratings is factored into a product of matrices representing latent factors for the items (in this case books) and the users.
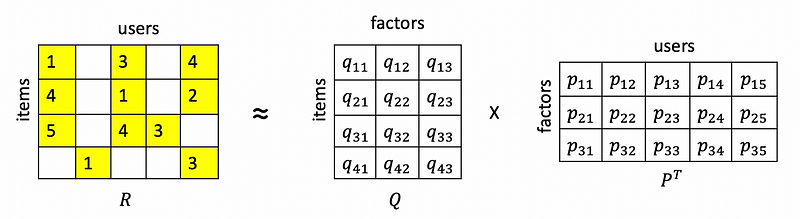
Considering the figure above, notice how the rating matrix, R, has missing values in some places. The matrix factorization algorithm uses a procedure such as gradient descent to minimize the error when predicting existing ratings using the matrix factors. Thus, an algorithm like SVD builds a recommendation system by allowing us to “fill in the gaps” in the rating matrix, predicting the ratings that each user would assign to each item in the dataset.
Starting with an input matrix A, SVD actually factorizes the original matrix into three matrices as demonstrated in the equation below.
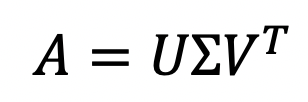
We can map these new matrices to the rating matrix R and the item and user factors Q and P as follows:
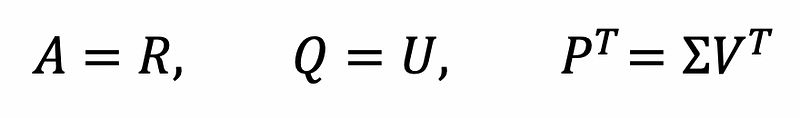
In the case of our book recommendation system, the SVD algorithm will represent the rating matrix as a product of matrices representing the book factors and user factors respectively. Of course, this is a very brief explanation of the SVD algorithm without all of the mathematical details but if you want a more detailed explanation of this algorithm, you should check out the Stanford CS 246 lecture notes.
In the code below, I cross-validated an SVD model using three-fold cross-validation.
from surprise import SVD
from surprise.model_selection import cross_validate
svd = SVD(verbose=True, n_epochs=10)
cross_validate(svd, data, measures=['RMSE', 'MAE'], cv=3, verbose=True)
Running the code above produced the following output.
Fold 1 Fold 2 Fold 3 Mean Std
RMSE (testset) 0.8561 0.8577 0.8551 0.8563 0.0011
MAE (testset) 0.6753 0.6764 0.6746 0.6754 0.0007
Fit time 20.21 22.62 23.25 22.03 1.31
Test time 3.18 4.68 4.79 4.22 0.74
We can also train the model on the entire dataset using the fit method after converting the dataset for cross-validation into a Surprise Trainset object using the build_full_trainset method.
trainset = data.build_full_trainset()
svd.fit(trainset)
Generating Rating Predictions
Now that we have a trained SVD model, we can use it to predict the rating a user would assign to a book given an ID for the user (UID) and an ID for the item/book (IID). The code below demonstrates how to do this with the predict method.
svd.predict(uid=10, iid=100)
The predict method returns the Prediction shown below, which contains a field called est that indicates the estimated book rating for this specific user.
Prediction(uid=10, iid=100, r_ui=None, est=4.051206489275292, details={'was_impossible': False})
Based on the output above, we can see that the model predicted that this specific user would give a four-star rating (roughly) to the book corresponding to an IID of 100. The model doesn’t directly recommend books, but we can use this rating prediction utility to identify what books a user would likely enjoy, which allows us to justify recommending them to a user.
Generating Book Recommendations
Using this rating prediction utility, I defined the following utility functions below for generating book recommendations.
https://gist.github.com/AmolMavuduru/aad95a6ffe227cd678e0fbe0380bb94d
The generate_recommendation function generates a book recommendation for a user by iterating through the shuffled list of book titles and predicting the user ratings for each title until it finds a book with a rating at or above the specified threshold that qualifies it for being recommended to a user. Shuffling the book titles at the beginning adds some randomness to the book recommendation.
generate_recommendation(1000, svd, books_metadata)
Running the function as demonstrated above produced the output below (note that due to the randomness of the function, you may get a different recommendation).
[{'id': 7034,
'isbn': '1402792808',
'authors': 'Corban Addison',
'title': 'A Walk Across the Sun',
'original_title': 'A Walk Across the Sun'}]
Based on the output above, we can see that the function returns a dictionary with metadata about the book that was recommended. Running this function multiple times will produce multiple book recommendations. After a user reviews a book, we can add that data to the rating data and retrain the model to produce an even better recommender system.
Visualizing the Book Factors Using t-SNE
We can take this project a step further and actually visualize the similarity between books based on the book factor matrix, referred to as Q in the previous diagram used to explain matrix factorization models.
This 10,000 x 100 matrix has a 100-dimensional vector for each book, which is too many dimensions for us to visualize intuitively, but we can use a dimensionality reduction technique to represent each book as a two-dimensional point in space. In the code below, I used a technique called t-SNE (t-Distributed Stochastic Neighbors Embedding) to represent each book as a two-dimensional point and stored the results in a data frame.
from sklearn.manifold import TSNE
tsne = TSNE(n_components=2, n_iter=500, verbose=3, random_state=1)
books_embedding = tsne.fit_transform(svd.qi)
projection = pd.DataFrame(columns=['x', 'y'], data=books_embedding)
projection['title'] = books_metadata['original_title']
After creating this data frame with two-dimensional points for each book, I used Plotly to create a visualization with each point corresponding to a book in the original dataset.
import plotly.express as px
fig = px.scatter(
projection, x='x', y='y'
)
fig.show()
https://datapane.com/u/amolmavuduru/reports/books-scatter-plot/
Based on the plot produced above by the Plotly code, we can see that the points representing the 10,000 books seem to follow a two-dimensional normal distribution. We can explain this distribution with the following theories about the books in the dataset:
- Some books may be generally popular among a wide range of audiences and thus correspond to points in the center of this scatterplot.
- Other books may fall into very specific genres such as vampire novels, mystery novels, and romance that are popular among specific audiences. These books may correspond to points away from the center of the plot.
To actually look at the book titles associated with each point, I defined a specific function for plotting a list of books given their titles. Note that I used Datapane to display the visualizations embedded in this article. In the code below, I added a function argument for publishing the resulting plot as a Datapane report.
import datapane as dp
def plot_books(titles, plot_name):
book_indices = []
for book in titles:
book_indices.append(get_book_id(book, books_metadata)-1)
book_vector_df = projection.iloc[book_indices]
fig = px.scatter(
book_vector_df, x='x', y='y', text='title',
)
fig.show()
report = dp.Report(dp.Plot(fig) ) #Create a report
report.publish(name=plot_name, open=True, visibility='PUBLIC')
Using the code below, I plotted the points associated with the first 30 books in the dataset.
books = list(books_metadata['title'][:30])
plot_books(books, plot_name='books_embedding')
https://datapane.com/u/amolmavuduru/reports/books-embedding/
This visualization allows us to see the similarities between different books. Books located closer to each other tend to perform similarly when it comes to ratings provided by similar users. For example, we can see that Catching Fire and Divergent, two novels from the Hunger Games and Divergent series respectively, were popular among similar users.
Summary
- Surprise is an easy-to-use Python library that allows us to quickly build rating-based recommender systems without reinventing the wheel.
- Surprise also gives us access to the matrix factors when using models such as SVD, which allows us to visualize the similarities between the items in our dataset.
As mentioned earlier, I have included the code for all of the examples in this article on GitHub.
Join My Mailing List
Do you want to get better at data science and machine learning? Do you want to stay up to date with the latest libraries, developments, and research in the data science and machine learning community?
Join my mailing list to get updates on my data science content. You’ll also get my free Step-By-Step Guide to Solving Machine Learning Problems when you sign up!
Sources
- N. Hug, Surprise: A Python library for recommender systems, (2020), Journal of Open Source Software.
- Z. Zajac, Goodbooks-10k dataset, (2017), Kaggle.
- J. Leskovec, Stanford CS 246 Mining Massive Datasets Lecture Notes, (2015), Stanford Network Analysis Project.